Pseudonymisierung und Anonymisierung
R 2.5.0
Beschreibung
Die Verwendung von Originaldaten zu Testzwecken bietet aus Testsicht die Vorteile, dass sie wirklich existieren, realistisch, konsistent und im Zeitverlauf historisch valide sind. Auf der anderen Seite stellt sich die datenschutzrechtliche Problematik bei der Verwendung von Echtdaten. Zu prüfen ist daher, ob die Verwendung von personenbezogenen Daten zu Testzwecken nicht gegen den Zweckbindungsgrundsatz sowie den Grundsatz der Datenminimierung verstößt. Trifft dies zu, ist der Einsatz von Echtdaten auf Testumgebungen zu vermeiden.
Stattdessen sollten die Testumgebungen entpersonalisiert werden. Dazu können Methoden wie z.B. die Pseudonymisierung oder Anonymisierung der personenbezogenen Daten eingesetzt werden.
Im Gegensatz zur Anonymisierung bleiben bei der Pseudonymisierung Bezüge verschiedener Datensätze, die auf dieselbe Art pseudonymisiert wurden, erhalten. Das bedeutet, dass z.B. ein Originalwert durch einen anderen Wert ersetzt wird und die Zuordnung in einer entsprechenden Tabelle gespeichert wird. Bei Bedarf kann das Original so wieder rekonstruiert werden. Diese Zuordnungstabelle kann getrennt von den Systemen, Anwendungen und Datenbanken aufbewahrt werden.
Diese Tabelle stellt ein Sicherheitsrisiko dar, denn mit ihr lassen sich die realen persönlichen Daten zurückverfolgen. Aus Test- und QS-Sicht muss allerdings festgehalten werden, dass ein pseudonymisierter Testdatenbestand allerdings im Regelfall eine tiefere fachliche Güte aufweist.
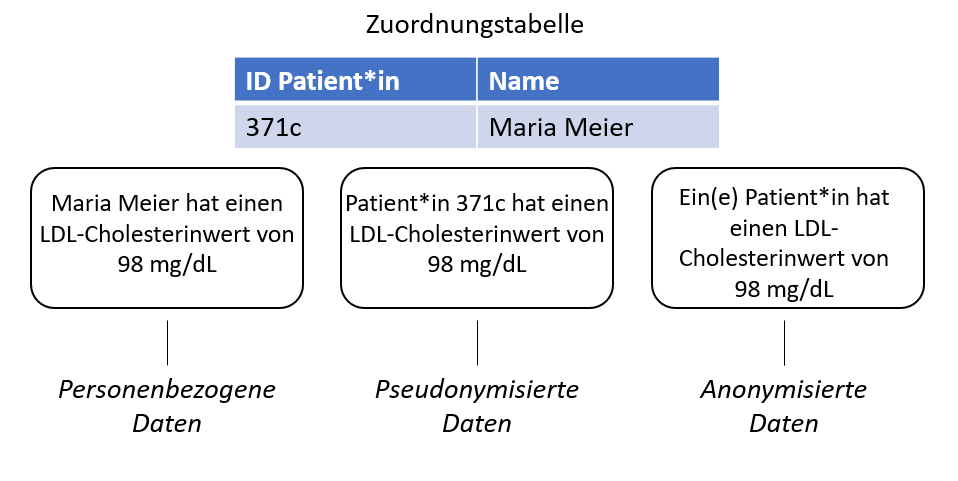
Die Anonymisierung der Testdaten hingegen ist eine Stufe strikter als deren Pseudonymisierung. In diesem Fall werden die Originalwerte und deren Zuordnung ausgeschlossen, sodass keine Rückschlüsse auf die Originaldaten mehr möglich sind. Bei der Anonymisierung verschwinden die Daten des einzelnen Individuums in der Masse und der Bezug kann nicht wieder hergestellt werden. D.h. auch die Fehlerfindung wird unter Umständen sehr erschwert.
Bei der Planung der Testmaßnahmen und dem passenden Einsatz von geeigneten Testdaten kann die Beteiligung der Datenschutzbeauftragten hilfreich sein.
Neben der erschwerten Einhaltung des Datenschutzes und der Absicherung vor Datenmissbrauch müssen bei der Verwendung von Echtdaten für Tests außerdem folgende Besonderheiten in die Überlegung und Planung aufgenommen werden:
-
Die Zuordnung von produktiven Daten zu Testfällen muss geschaffen werden
-
Wenn mehrere Systeme übergreifend beteiligt sind, müssen deren Echtdaten für die Tests zusammen passen
-
Junge Anwendungen haben womöglich noch zu wenig Daten / ältere womöglich "Datenleichen"
-
Für ganz neue Anforderungen könnte es ggf. noch keine eigenen Echtdaten geben
-
Die Aufwände für die Erstellung der Datenabzüge müssen mit eingeplant werden
Was sind personenbezogene Daten?
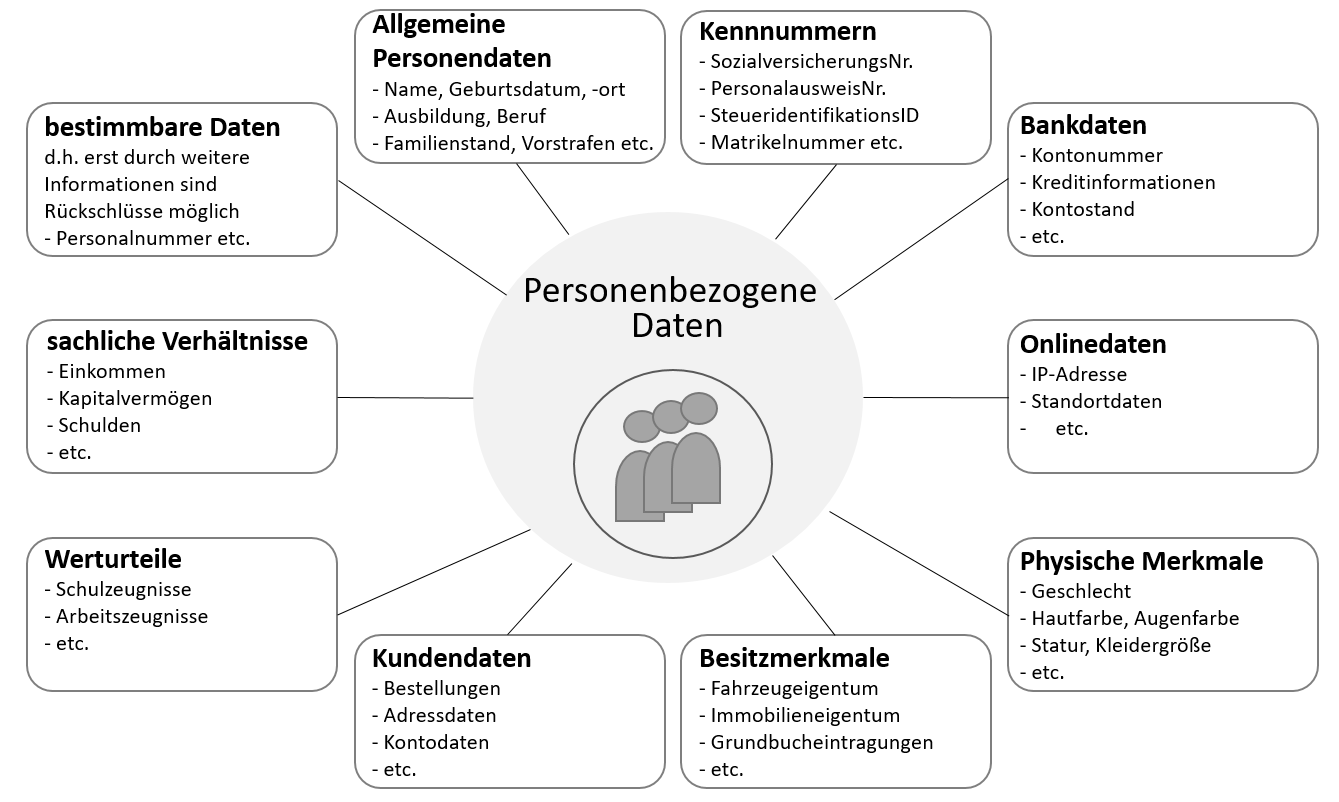
Gemäß §46 des Bundesdatenschutzgesetzes (BDSG) sind es "alle Informationen, die sich auf eine identifizierte oder identifizierbare natürliche Person beziehen."
Beispiele:
-
allgemeine Personendaten (Name, Geburtsdatum, Geburtsort, Anschrift, E-Mail-Adresse, Telefonnummer usw.)
-
Kennnummern (Personalausweisnummer, Matrikelnummer, Steueridentifikationsnummer, Sozialversicherungsnummer usw.)
-
Bankdaten (Kontonummer, Kontostände, Kreditinformationen usw.)
-
Online-Daten (IP-Adresse, Standortdaten usw.)
-
physische Merkmale (Geschlecht, Hautfarbe, Haarfarbe, Augenfarbe usw.)
-
Besitzmerkmale (Eigentum, Grundbucheinträge, Kfz-Zulassungsdaten usw.)
-
Kundendaten (Bestellungen, Adressdaten usw.)
-
Werturteile (Arbeitszeugnis, Schulzeugnis usw.)
Darüber hinaus existieren personenbezogene Daten, die eines erhöhten Schutzes bedürfen (§46 14a-e BDSG):
-
Daten, aus denen die "rassische oder ethnische Herkunft, politische Meinungen, religiöse oder weltanschauliche Überzeugungen oder Gewerkschaftszugehörigkeit hervorgehen.
-
genetische Daten
-
biometrische Daten zur eindeutigen Identifizierung einer natürlichen Person
-
Gesundheitsdaten
-
Daten zum Sexualleben oder der sexuellen Orientierung"
Daten künstlich erzeugen oder echte Daten verfremden?
Vor dem Hintergrund, dass Testdaten keine echten Personendaten beinhalten sollen, gibt es nun verschiedene Ansätze, geeignete Testdaten zu erzeugen:
-
Pseudonymisierung oder Anonymisierung echter Daten
Hier werden die Anteile der Daten, die eine Person eindeutig identifizieren können, aus den Produktivdaten so abgeändert, dass der Bezug zur echten Person nicht mehr bzw. nur mit Zusatzinformationen hergestellt werden kann. Bei der Anonymisierung geschieht die Verfremdung endgültig und bei der Pseudonymisierung werden Pseudonyme für persönliche Identifikatoren verwendet. Ein simples Beispiel ist der Austausch des Namens "Herbert Müller" durch das Pseudonym "Hermann Meier". Die Zuordnung lässt sich nur durch zusätzliche Informationen (z.B. separat geführte Tabelle mit Zugriffsbeschränkung) wiederherstellen.
-
Künstliche ("synthetische") Daten
Es ist außerdem möglich, die Daten komplett künstlich zu erzeugen und beispielsweise aus einer Liste an gültigen Nachnamen, Vornamen und formal gültigen aber falschen Telefonnummern Testdatensätze zusammenzusetzen. Die Testdaten haben keinen Bezug zu den Originaldaten. Tools können unterstützen und statistische Modelle verwenden, die auf den Originaldatensätzen basieren. Bei solchen künstlichen Daten besteht kein Risiko, Datenschutz oder Privatsphäre zu verletzen.

Strategien bei der Synthetisierung von Testdaten
| Zufallsgesteuert (randomisiert, auch: Dummy- oder Mockdaten) |
Modellbasiert (Regelbasiert) |
KI | |
|---|---|---|---|
Aufwand |
Gering |
Mittel-Hoch |
Mittel-Hoch; eher nachgelagerte Validierung |
Realitätsnähe |
Sehr gering |
Hängt vom Modell ab: kann sehr gut sein |
Anspruch: maximal gut |
Datenschutz |
maximal |
maximal |
Zugang zu Echtdaten zu Trainingszwecken erforderlich |
Datenmenge |
Manuelle Eingabe: gering |
Beliebig hoch |
Beliebig hoch |
Zufallsgesteuert bedeutet, dass Werte bestimmter Variable zufällig belegt werden (z.B. Alter von 0-85, Geschlecht abwechselnd m/w/d, Beruf aus einer Liste von vorgegebenen Möglichkeiten).
Beim modellbasierten (auch: regelbasierten) Ansatz wird ein Modell entwickelt, dass den Daten aus der Echtwelt möglichst nahe kommt (Grundlage sind Statistiken, bekannte Erhebungen, Schätzungen, Prognosen). Das kann insbesondere wichtig sein, wenn die Daten voraussichtlich bestimmten Mustern unterliegen. Beispielsweise könnte es sein, dass es bestimmte Verteilungen gibt, die nachgebildet werden sollen (Verhältnis männlich zu weiblich, Schwerpunkt auf bestimmte Bildungsabschlüsse). Vielleicht gibt es aber auch noch gar keine Echtdaten und nur Annahmen darüber wie die Daten vielleicht später einmal aussehen könnten.
Der Einsatz von Künstlicher Intelligenz wird seit einiger Zeit auf vielen Gebieten propagiert. Bei der Synthese von Testdaten findet zunächst eine Analyse der Echtdaten statt, sie bilden die Grundlage und den Ausgangspunkt. Zugang zu den Echtdaten muss also möglich, bzw. vorhanden sein). Mithilfe von statistischen Analysen der Echtdaten werden verschiedene Lage- und Streuungsmaße (deskriptiv, bivariat) ermittelt. Diese sind dann wiederum Grundlage für den Aufbau eines Datensatzes, der eng an den Produktionsdaten dran ist (qua Durchschnittsverteilung z.B.). KI-Modell muss auf den Produktivdaten trainiert werden!
Vorteile von Testdatengeneratoren
-
Schnell auch große Datenmengen erstellen
-
Leichter dokumentieren können
-
Nachvollziehbarkeit durch Archivierung
-
Kontrolliert aufgebaute Datenbestände
Nachteile von Testdatengeneratoren
-
Entwicklung eines Modells notwendig
-
Synthetisches Modell oder alternativ Echtdatenzugriff als Grundlage eines (statistischen) Modells
-
Aufwände für Modellpflege und –anpassung
-
Fachliche Tiefe fraglich
-
Bias möglich
-
Caching-Probleme
-
Gleichmäßige Verteilung (auch bei Namen und Vornamen)
-
Randbereiche, Freak-Cases und Grenzbedingungen
Ermittlung der Domänen-Objekte
Soll ein modellbasierter Testdatengenerierungsansatz eingesetzt werden sind genaue Kenntnisse des Datenmodells aber auch der Fachklassen (domain objects) notwendig. Die entstandenen Generate müssen fachlich und technisch validiert werden, was eine eigene Testaktivität bedeutet: Test und Qualitätssicherung der Testdaten
Probleme bei der Modellentwicklung
-
Genauigkeit der Datenverteilung: Schwierigkeit die genaue Verteilung der realen Daten zu reproduzieren
-
Aufrechterhaltung von Korrelationen: Berücksichtigung von Korrelationen und Abhängigkeiten zwischen Variablen
-
Validierung und Qualitätssicherung: Synthetische Daten müssen umfangreich validiert werden
Quellen
-
DSN Holding GmbH, Echtdaten-sind-keine-Testdaten, abgerufen am 09.07.2024
-
Entwickler.de - Software und Support Media GmbH, Testdaten-eine Falle der DSGVO?, abgerufen am 09.07.2024
-
redbots people GmbH - Testdaten aus Produktion - Für und Wider, abgerufen am 10.07.2024
-
Bundesdatenschutzgesetz, BDSG Begriffsbestimmung personenbezogene Daten, abgerufen am 10.07.2024
-
VFR Verlag für Rechtsjournalismus, Was sind personenbezogene Daten?, abgerufen am 10.07.2024
-
Test der Electronic Frontier Foundation (EEF), Gefahr der Deanonymisierung durch die Historie des Web-Browsers, abgerufen am 11.07.2024
-
SIGS DATACOM Fachinformation für IT-Professionals, Keine Daten? Keine Tests!, abgerufen am 26.08.2024
-
Firma Syntho (Amsterdam), Was sind synthetische Daten?, abgerufen am 26.08.2024
-
Piwik pro GmbH Berlin, Was sind personenbezogene Daten, PII und Non-PII?, abgerufen am 26.08.2024
-
Kobold AI UG, Was ist Synthetic Data?, abgerufen am 26.08.2024
-
Johannes Keppler Universität Linz, univariate Verteilungen, abgerufen am 26.08.2024
-
Wikipedia, Personal Data, abgerufen am 26.08.2024
-
QuestionPro GmbH, Synthetische Daten: Was sie sind, Arten, Methoden und Verwendung, abgerufen am 26.08.2024